Эксперименты с обучением методов распознавания дорожных знаков на синтетических данных

Введение.
Задача распознавания дорожных знаков активно исследуется уже не одно десятилетие. Если будет создан метод, работающий с достаточной точностью, его можно использовать в системах помощи водителю, инвентаризации объектов придорожной инфраструктуры или для автоматизированного создания навигационных карт.
Дорожные знаки сделаны, чтобы быть заметными и легко читаемыми и это делает их хороших объектом для автоматического распознавания. В то же время автоматические алгоритмы должны распознавать знаки в условиях внутри классовой изменчивости, изменения освещенности, положения точки наблюдения, размытия и перекрытий. Лучшие на сегодняшний день алгоритмы опираются на машинное обучение и требуют наличия большой и репрезентативной обучающей коллекции, чтобы обойти все вышеперечисленные проблемы. Для получения такой коллекции необходимо просмотреть и разметить тысячи километров проезда. Задача становится особенно сложной в случае редко встречающихся классов знаков. Учитывая тот факт, что знаки в разных странах отличаются друг от друга – необходимо собирать подобную коллекцию для каждой новой страны. Чтобы обойти вышеописанную проблему разметки мы предлагаем использовать для обучения синтетически созданную обучающую выборку. Также мы предлагаем алгоритм, предполагающий, что известны параметры трансформаций, которым были подвержены изображения из обучающей выборки. Данное предположение является верным в случае синтетической обучающей коллекции. Наш алгоритм способен не только распознавать класс знака, но и сегментировать его от фона.
Обзор литературы.
Обобщенный алгоритм обнаружения и распознавания объектов состоит из трех этапов. На первом этапе ограничивающий прямоугольник объекта выделяется на изображении. Далее происходит уточнение положения объекта внутри полученного ограничивающего прямоугольника, и объект сегментируется от фона. На третьем этапа происходит распознавание класса знака. В данной работе мы рассматриваем задачи, решаемые на первом и втором этапе алгоритма.
Согласно классификации, предложенной в [1], методы распознавания автодорожных знаков можно разделить на две группы – основанные на похожести знаков и основанные на признаках. В методах, основанных на похожести, распознаваемому изображению присваивается метка класса ближайшего к нему прототипа из обучающей выборки. В [2] предложен новый вариант AdaBoost названный SimBoost, спроектированный для распознавания двух классов – “похожие” и “разные”. Класс входного изображения определяется с помощью поиска ближайшего соседа с инвертированной уверенностью SimBoost в качестве метрики расстояния. В [3] предложен гибридный метод на основе классификаторов ближайшего соседа и случайного леса на HOG дескрипторах [4]. Описанный в [3] подход на основе ближайшего соседа похож на предложенный нами, но мы добиваемся лучших результатов за счет использования двухэтапной схемы и синтетических данных.
В подходе, основанном на признаках, входное изображение описывается с помощью какого-либо дескриптора и классификатор, предсказывающий класс знака, обучается на извлеченных признаках. В [5] предложена двухэтапная схема классификации. На первом этапе знаку присваивается метка одной из 11 групп, на основе признаков цвета и формы. Затем знак отделяется (сегментируется) от фона с помощью маски знака, заранее определенной для каждой группы. RGB значения пикселей, лежащих внутри маски знака, подаются на вход SVM-классификатора с гауссовым ядром. В предложенном нами методе мы можем точнее определить маску знака за счет использования большего количества вариаций. В [6] результаты работы многослойной нейронной сети (MLP) и свёрточной нейронной сеть (CNN) объединяются в комитет. MLPобучается на HOG дескрипторах, в то время как CNN – на случайным образом отмасштабированных, сдвинутых и повернутых цветных изображениях. Авторы [7] также использовал CNN с обучением на изображениях, преобразованных в цветовое пространство YUV, с Y каналом, обработанным с помощью локального и глобального выравнивания контраста.
Создание синтетической обучающей выборки.
Для создания синтетических изображений знаков нами был использован алгоритм, описанный в статье [8]. Визуализация результатов работы основных шагов алгоритма приведена на рисунке 1. На вход алгоритма генерации подается пиктограмма знака и маска фона, которую легко выделить по пиктограмме. Далее к пиктограмме знака применяется набор трансформаций, состоящий из вариации интенсивности и насыщенности, поворотов вокруг трех осей, перспективных преобразований, добавления шумов и смещений. На последнем этапе к полученному изображению знака с помощью алгоритма смешивания добавляется фон, вырезанный из реальных изображений. В результате получается выборка, состоящая из синтетических изображений знаков и масок фона. Для каждого примера из выборки известно преобразование, которому он был подвержен. Визуализация результатов работы алгоритма приведена на рисунке 2.

Алгоритм генерации синтетических данных.

Пример получаемых синтетических данных.
Описание предложенного алгоритма.
После получения синтетической обучающей выборки мы извлекаем HOG дескрипторы из всех примеров и используем классификатор на основе поиска ближайшего соседа для присвоения входному изображению метки класса знака.
Метод на основе поиска ближайшего соседа обладает простым свойством – чем больше данных в обучающей выборке, тем лучше результаты распознавания. Наш алгоритм генерации синтетических данных содержит 16 параметров трансформаций. Если каждый параметр при генерации будет представлен хотя бы тремя значениями, то мы получим больше 50 миллионов синтетических примеров только на один класс. Чтобы решить данную проблему мы разбиваем поиск ближайшего соседа на два этапа. На первом этапа мы определяем приближенные параметры трансформации за счет поиска по выборке, сгенерированной с параметрами, варьируемыми в широком диапазоне значений с большим шагом. На втором этапе мы ищем ближайшего соседа в окрестности трансформации, определенной на первом этапе.
В случае дорожных знаков на первом этапе мы определяем приближенные параметры трансформации и маску знака. Далее мы отделяем знак от фона и удаляем смещения по краям, используя найденную маску. И производим поиск ближайшего соседа в окрестности найденной трансформации, чтобы получить окончательную метку класса. Визуализация работы алгоритма приведена на рисунке 3. Примеры четырех ближайших соседей, получаемых после первого этапа алгоритма, приведены на рисунке 4. Видно, что удается точно определить параметры трансформации, что позволяет отделить знак от фона.

Визуализация работы предложенного алгоритма распознавания: а) Поиск входного изображения среди трансформаций в широком диапазоне б) найдена приближенная трансформация и маска знака. Знак отделен от фона и выровнен в) поиск отделенного от фона знака в окрестности найденной трансформации г) присвоение класса знака.

Примеры четырех ближайших соседей, получаемых после первого этапа предложенного алгоритма.
Эксперименты и результаты.
Чтобы подтвердить эффективность классификатора на основе ближайшего соседа мы обучили на нашей синтетической выборке, состоящей из 100 000 изображений знаков, следующие типы классификаторов:
1) Linear Discriminant Analysis (LDA)
2) LinearSVM(LSVM)
3) Классификатор на основе Kближайших соседей (k-NN)
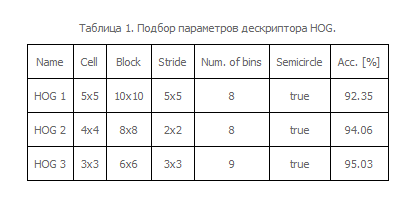
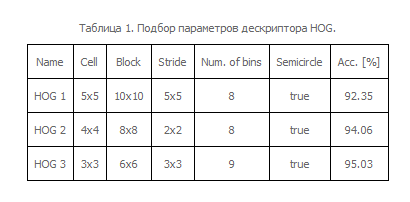
Мы провели сравнение получаемых точностей классификации на базе GTSTB [9]. Она состоит из 50000 изображений 43 классов знаков. Размеры встречаемых в коллекции знаков варьируются от 15x15 до 222x199 пикселей. Обучающая и тестовая выборка состоят из 39209 и 12630 изображений, соответственно. Мы тестировали предложенный алгоритм на тестовой части выборки и обучались на синтетических данных. Параметры дескриптора HOGбыли подобраны путем сравнения нескольких наборов параметров в связке с k-NNклассификатором. Результаты сравнения приведены в таблице 1. Для дальнейших экспериментов был использован набор параметров “HOG3”.
Все гиперпараметры классификаторов были подобраны с помощью метода скользящего контроля. Результаты классификации приведены в таблице 2. Тренировочные наборы № 1 и № 2 содержат синтетические и реальные данные соответственно. Из сравнения результатов для наборов № 1 и № 2 видно, что в случае обучения на синтетических данных LDA и LSVM работают намного хуже, чем в случае обучения на реальных данных. Мы объясняем эту разницу тем, что распределение, лежащее в основе генератора синтетических данных, намного сложнее и линейные классификаторы, такие как LDA и LSVM, не могут разделить получаемую выборку. В то же время нелинейный метод на основе поиска ближайшего соседа (k-NN) лучше справляется со сложной выборкой. Чтобы подтвердить наши выводы мы провели простой эксперимент, создав набор № 3, содержащий синтетические данные после этапа сегментации и выравнивания предложенного нами алгоритма. Результирующая выборка получилась проще, за счет отсутствия в генераторе синтетических данных ряда трансформаций. Видно, что ошибка классификации у LDA и LSVM упала в два раза. Лучшие на сегодняшний день методы классификации знаков на данной базе достигают точности 99.46% и основаны на объединении результатов работы нескольких глубоких нейронных сетей. Глубокими нейронными сетями называют такие нейронные сети, у которых количество слоев с настраиваемыми во время обучения весами больше двух. Хотя точность предложенного нами метода ниже, он лучше подходит для использования модуля распознавания в связке с модулем обнаружения, так как позволяет выровнять знак и отделить его от фона. Типичные ошибки предложенного алгоритма приведены на рисунке 5. Они вызваны отсутствием соответствующей трансформации в алгоритме генерации синтетических данных. К таким трансформациям относятся: перекрытия, блики, сильное размытие за счет движения камеры.

Типичные ошибки предложенного алгоритма.
Мы также протестировали предложенный нами метод на двух других базах знаков. На базе шведских знаков [10] на “visible” подмножестве изображений наш метод показал точность 97.47% на первой части и 99.13% на второй части. Сравнение с результатами из статьи создателей базы [11] провести невозможно, так как в статье заявлены результаты для одновременного обнаружения и распознавания знаков. На базе бельгийских знаков [12] нами достигнута точность в 95.57%. В [13] была получена точность в 97%, но распознаванию подвергались только обнаруженные, а значит самые простые, знаки.
Технические детали.
Модель предложенного двухуровневого классификатора занимает 10 Гб в оперативной памяти и состоит из 650000 синтетических изображений знаков с масками фона. Время классификации равно 0.3 секунды на одном современном процессоре. Процедура генерации синтетической выборки указанного размера занимает 15 минут и может быть существенно ускорена, так как большую часть времени занимают операции дискового ввода-вывода.
Заключение.
Предложен метод распознавания знаков дорожного движения, спроектированный для обучения на синтетически созданных данных. В методе предполагается, что для каждого обучающего примера известны преобразования, которым он был подвергнут. Описан алгоритм создания синтетической обучающей выборки. Метод распознавания работает на основе поиска ближайшего соседа в пространстве дескрипторов, полученных за счет извлечения градиентных признаков. Предложенный метод также позволяет отделить знак от фона и выровнять его границы, что в дальнейшем помогает на этапе классификации. Проведено тестирование метода на общедоступных базах знаков из трех стран. Получены результаты, сравнимые по точности с описанными в других статьях.
Работа поддержана РФФИ; грант №12-01-33085 по теме «Методы настройки вероятностных моделей в задачах анализа изображений, данных лазерного сканирования, компьютерного зрения».
авторы статьи: Чигорин А. А., Конушин А. С.
Список литературы
1.Dalal N., Triggs W. Histogram of oriented gradients for human detection
2.Paclik P., Novovicova J., Duin R. Building Road-Sign Classifiers Using a Trainable Similarity Measure
3.Ruta A., Porikli F., Watanabe S., Li Y. In-vehicle Camera Traffic Sign Detection and Recognition
4.Zaklouta F., Stanciulescu B., Hamdoun O. Traffic sign classification using K-d trees and Random Forests
5.Maldonado-Bascon S., Lafuente-Arroyo S., Gil-Jimenez P., Gomez-Moreno H., Lopez-Ferreras F. Road-Sign Detection and Recognition Based on Support Vector
6.Ciresan D., Meier U., Masci J., Schmidhuber J. A Committee of Neural Networks for Traffic Sign Classification
7.Sermanet P., Lecun Y. Traffic Sign Recognition with Multi-Scale Convolutional Networks
8.Моисеев Б., Чигорин А. Классификация автодорожных знаков с помощью свёрточной нейросети, обученной на синтетических данных
9.Stallkamp J., Schlipsing M, Salmen J., Igel C. Man vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition
10.Larsson F. Traffic signs dataset.
11.Larsson F., Felsberg M. Using Fourier Descriptors and Spatial Models for Traffic Sign Recognition
12.Timofte R. KUL Belgium Traffic Sign Classification Benchmark.
13.Timofte R., Zimmermann K., Gool Van L. Multi-view traffic sign detection, recognition, and 3D localization
- +1
-
 Magatron
Magatron
- Поделиться
Комментарии (18)